こんにちは。SRE の @chaspy です。
現在、新サービスを作成する際、そのデータベースには AWS Aurora(Postgres) を使用しています。
その作成には Terraform を用いており、いくつか適当な引数を入れると Terraform のコードが自動生成される仕組みを用意しています。
これで盤石...と思った1年前の私ですが、この仕組みにはいくつか問題点がありました。本記事ではその問題点とそれを改善した話をします。
既存の仕組みの問題点
以下、大きく2つの問題点がありました。
開発環境用のデータベースが本番環境用のデータベースのスナップショットからリストアされることが考慮されていない
開発環境用のデータベースには2種類あります。
- Terraform で作成され、その後、本番環境用のデータベースのスナップショットからリストアされない "注釈: 本番環境用のデータベースには個人情報が含まれる場合があるので、リストア時にはそれらの情報をマスクしています"
- script によって本番環境用のデータベースのスナップショットからリストアされる
本番環境用のデータベースのスナップショットからリストアされるということは当然先に本番用データベースが必要です。しかし特に何も指示がなければ通常、開発環境用のデータベースから先に作成するでしょう。
このようにユースケースと運用フローが十分に考慮されていなかったため、Terraform で開発環境用のデータベースを作成するが、あとでリストアがあったほうが便利だと気づき、script でリストアを行うが、Terraform で作成しているため二重定義になり、1度削除をする、など煩雑な手間が発生していました。
この点はもともとあったドキュメントに Overview と Example Workflow のセクションを追記することで整理しました。以下が実際のドキュメントです。社内固有の名称は適当な一般的な名前に変更しています。
Overview
There are several ways to create it, depending on your requirements.
Production Database
Create with Terraform.
Staging Database
If you want to make the data persistent
Create with Terraform
If you want to create from a snapshot of Production Database
Use Restore Script.
Example Workflow
If you want Database for these environments: - production - support (restored from production snapshot) - develop (restored from production snapshot) - qa (NOT restored from production snapshot)
production and support and develop
- Create a Production Database by Terraform
- Create an application role by Jenkins Job
- Set restoring script for support and develop
- Set database password to aws-secret-manager
- For production, use artifact by the Jenkins Job and set it as vault
- For develop and edge (and staging), set database password as text
qa
- Create qa Database by Terraform
- Create an application role by Jenkins Job
この経験から、単に自動化の仕組みを提供するだけでは不十分で、利用者のユースケースをヒアリングすべきであったと学びました。
本番環境用のデータベースの Password を設定するために SRE の作業が必要
Terraform のコードが簡単に生成できるようになった、これで勝った - そう思っていた1年前の自分が未熟だと気づけたことは、成長したとも言えるかもしれません。
そもそもなぜ RDS のセルフサービス化をしたかったかというと、最近の SRE Team のミッション - 自己完結化 - のために SRE の手を介さずにクラウドリソースを Developer 自身で作れる仕組みが必要だったからです。特に RDS は新サービス作成時にはかなりの場合で必要になります。
しかし、実際にやってみると、以下の2つの場面で SRE の手作業が必要でした。
- 本番環境用のデータベースを作成する際に、master user 用のパスワードを生成して暗号化する
- 本番環境用のデータベースを作成後、master user と別に、アプリケーションが使用する role を生成する
本番環境用のデータベースを作成する際に、master password を生成して暗号化する
AWS で RDS(Aurora) を作成するときは、初期状態で生成される master user のパスワードを設定する必要があります。
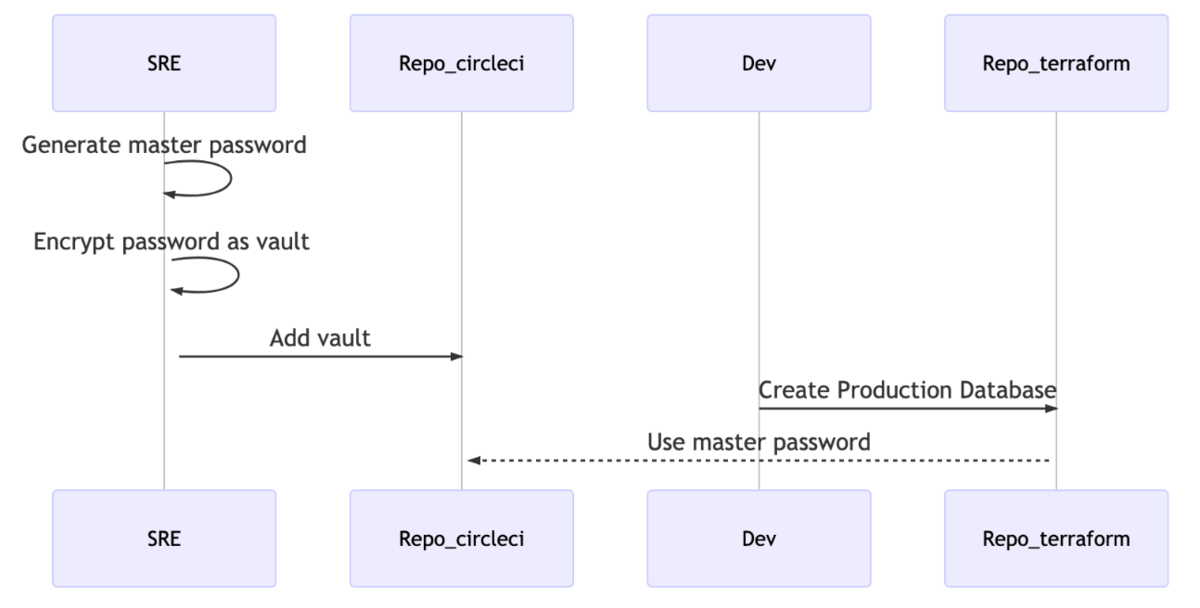 \
Terraform で作成する際も、本番環境のデータベースパスワードをコードに書くわけにもいかないため、SRE がこっそり強度の高いパスワードを生成し、CircleCI の環境変数に設定したものを使用しています。(注釈:CircleCI の環境変数は自作のツールを用いてコード管理されており、ansible vault を使って暗号化しています)
\
Terraform で作成する際も、本番環境のデータベースパスワードをコードに書くわけにもいかないため、SRE がこっそり強度の高いパスワードを生成し、CircleCI の環境変数に設定したものを使用しています。(注釈:CircleCI の環境変数は自作のツールを用いてコード管理されており、ansible vault を使って暗号化しています)
このままではいくら Terraform のコード生成を自動化したとしても、環境変数の生成を SRE が行わなければならず、完全なセルフサービス化にはなりません。
この問題に対しては、「そもそも master user のパスワードを保管しない」、という結論に達しました。
Terraform のコードには適当な値で平文で作成後、後述する作成後にアプリケーションが使用する role を作成する際にパスワードを暗号強度の高い別の値に変更し、どこにも保存をしない、という方法を取りました。
そもそもRDS(Aurora) の master user のパスワードは AWS の RDS(Aurora) に対する変更権限があれば、cli(aws rds modify-db-cluster) 等を使って容易に変更可能です。そのため、推測の難しい値をセットしておいて、必要な時に変更すれば十分だと判断しました。
本番環境用のデータベースを作成後、master user と別に、アプリケーションが使用する role を生成する
データベースの作成後、権限を適切に絞るために、master user とは別に、アプリケーションから接続するための、データベースのオーナーとなる role を作成する必要があります。具体的には以下のコマンドを打っているだけです。(Aurora Postgres の場合)
# 環境変数はその名前の通りのものが入ります
CREATE ROLE ${APP_USERNAME} WITH LOGIN PASSWORD '${APP_PASSWORD}';
ALTER DATABASE ${DATABASE_NAME} OWNER TO ${APP_USERNAME};
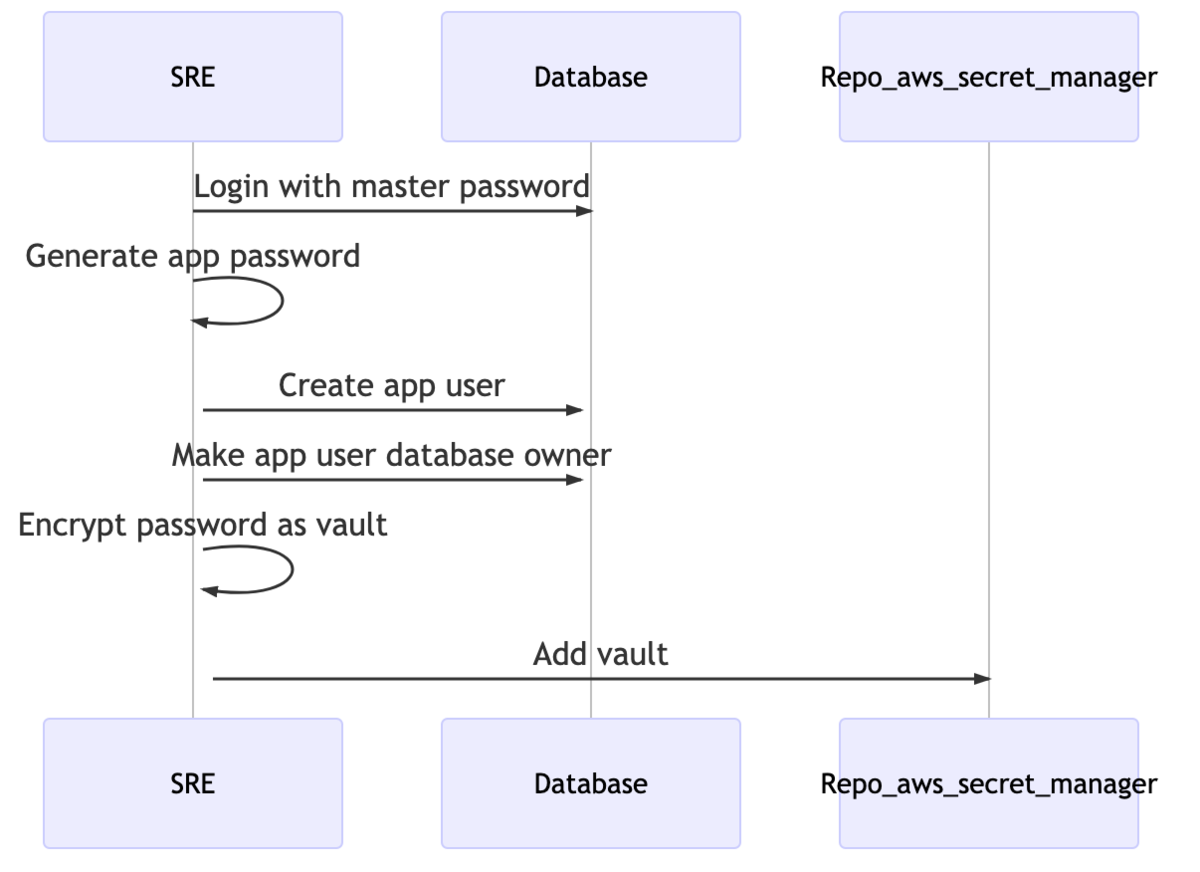
これは単なるコマンドですので、対象の RDS に接続できる場所から処理を自動化できます。
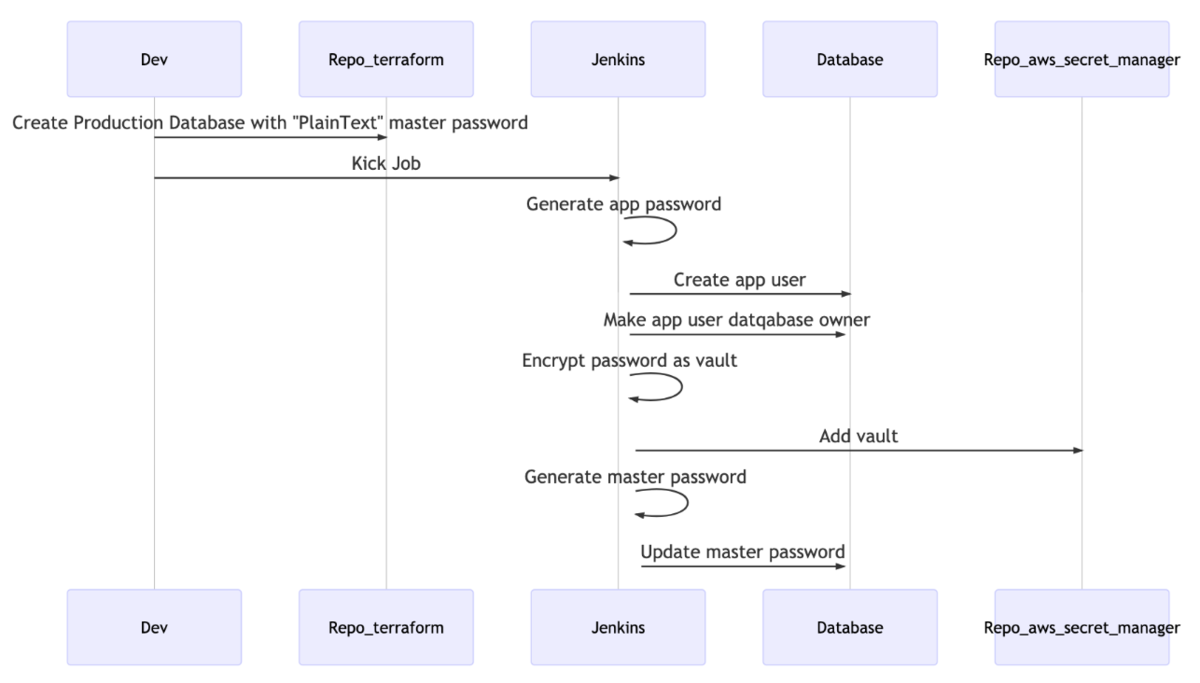
そこで、前述した master user のパスワードの変更を含めた、以下の処理を行う Jenkins Job(注釈: Jenkins は Production の VPC に接続できる別の VPC に EC2 インスタンスとして存在します)を作成しました。
- アプリケーションが接続するための role を作成
- 上記 role のパスワードを暗号化し、Job の Artifact 化
- master user のパスワードを更新
この Jenkins Job を Terraform による本番環境用のデータベース作成後に Developer に叩いてもらうことで、SRE の手作業を(ようやく)完全に排除できました
工夫した点
今回の変更で意識したことは以下の2点です。
- ひとつのことをうまくやる(UNIX 哲学)
- 既存の運用を可能な限り変えない
ひとつのことをうまくやる(UNIX 哲学)
自動化といっても、その対象は AWS - RDS/Aurora, PostgreSQL, AWS Secret Manager と複数のリソースが関係しており、自動化の手段・ワークフローも様々です。
今回の例では、データベースの作成(Terraform)、PostgresSQL 上の role 作成(Jenkins Job)、アプリケーションから使うために AWS Secret Manager へのパスワードの格納といったことがあげられます。
そのため、今回は上記の3つのリソースに対してそれぞれ自動化を別にすることで、単一のジョブでは単一のことを行うことによりワークフローがすっきりしました。
- Terraform によるデータベースの作成
- Jenkins Job による PostgreSQL での role 作成
- AWS Secret Manager へのアプリケーション用のパスワードの格納
仮に Terraform によるデータベースの作成をトリガーに、アプリケーション用のパスワードの格納まで自動化することもできたかもしれませんが、それぞれの処理に渡すための情報が多くなってしまい、複雑なプログラミングが必要になってしまいます。
今回は Jenkins Job による PostgreSQL での role 作成 だけを行うことにし、ansible-vault で暗号化したパスワードを Job の Artifact として取り出し、AWS Secret Manager への格納は対象のリポジトリに人間が手作業でプルリクエストを送る必要があります。確かに手間は増えるのですが、各処理が疎結合になり処理がシンプルになるので、現在の頻度を考えるとこのぐらいの手作業は十分許容できると判断しました。
既存の運用を可能な限り変えない
前述したように、既に Terraform でのデータベース作成 と AWS Secret Manager へのアプリケーション用のパスワードの格納 に関しては既存の仕組みが存在します。運用を変えることは、利用者に学習コストを強いてしまうことに他なりません。
既存の運用から変化する部分が少なければ、チームメンバーからの理解も得やすく、失敗したときの切り戻しも容易となります。
おわりに
あらためて考えてみれば最初からできたことかもしれませんし、やってみれば簡単でもっとはやくできたことかもしれません。その点は過去の自分の至らない点だと反省しつつ、仕組みを作るときは実際に使用者の立場での検証や、ユースケースのヒアリングが重要であることや、自動化を行うときは必要となる頻度と省略できる手間(メリット)を考慮し、保守性のために疎結合に設計したほうが良いといったことを学ぶことができました。
たかが自動化、されど自動化。その勘所を掴む良い事例であったと思います。
Quipper では世界の果てまで学びを届けたい仲間を募集しています