Quipperでは4つのMongoDBクラスター(国内2&グローバル2)を本番環境で運用しています。 これまでに幾度も壁にぶつかりながら培ったMongoDBのチューニングの事例を紹介します。
- メモリの大きいインスタンスを使う
- I/O性能を最高にする
- WiredTigerのキャッシュ割当をサーバメモリの70%まで引き上げる
- WiredTigerのTickets数を増やす
はじめに
本記事で書かないこと
- クエリのチューニング
- AWS, MongoDB Cloud Manager, MongoDB Atlasのサービスの説明
- Replica SetやSharded Clusterの解説
解説はMongoDB Universityがわかりやすいの紹介しておきます。(無料)
M103: Basic Cluster Administration
現状
QuipperではMongoDBを中心に据えながらマイクロサービスの中でAWSのRDSも利用しています。 現在MongoDB Cloud ManagerからMongoDB Atlasへ段階的に切り替えています。
- MongoDBバージョン
- 3.6 & 4.0
- MongoDB Cloud Managerの構成
- Primary, Secondary, Hiddenサーバを使ったReplica Set
- シャーディングなし
- MongoDB Atlasの構成
- 2 shardsのクラスター
ここからが本編です。
メモリの大きいインスタンスを使う
いきなりチューニングと呼べないかもしれませんが、多くのケースはこれで解決する可能性があります。
一般的なMongoDBのユースケースでは、メモリに負荷が集中します。MongoDB互換ではありますがAmazon DocumentDBでもメモリ最適化インスタンスを使っているし、MongoDB Atlasも同様です。
とくにまだサーバが小さいのであれば、メモリを増やすことで増えるサーバコストよりも、単純な作業で終わるメリットの方が大きいのではないでしょうか。
I/O性能を最高にする
書き込みが多いユースケースではディスクI/Oがボトルネックになる可能性があります。Quipperではユーザーの学習動画の閲覧状況を頻繁に保存したりすることでMongoDBのプライマリにI/O負荷が集中します。
XFSファイルシステム
MongoDBのストレージエンジンがWiredTigerの場合にext4ではなくXFSを使うことが公式ドキュメントで強く推奨されています。ストレージエンジンの選択肢は実質的にWiredTigerのみです。
インスタンスストアをdbpathに使う
みなさんはEC2のインスタンスストアを使うことがありますか? しかもDBサーバの本番データを置くディスクとして使うことがありますか?はじめはぼくも抵抗がありましたが、本番環境でもインスタンスストアを使っています。
I/Oがボトルネックになる場合は、もっともI/Oが速くなる構成を組むことでスループットを最大にできます。NVMeという今日もっとも高速なインターフェースで直に接続されたSSDを利用することができるので、EBSのProvisioned IOPSをMAX上げるよりも速い速度が出ます。
インスタンスストアを使うデータベースは、EBSを使ったHiddenサーバとレプリケーションすることで信頼性を高めています。 じつはインスタンスストアを使ったり、Hiddenで永続化する構成は、MongoDB AtlasでNVMe SSDを選んだ場合にも裏側で使われています。
i3enを使う(AWSでI/Oが一番速いインスタンスタイプ)
2019年に登場したi3en+インスタンスストアの組み合わせが現在のAWSでは一番I/Oが速い構成です。
i3enサーバの性能を見るとインスタンスのサイズがあがるごとに数値が2倍になっていますが、ディスクの本数が増えることで合計したI/O性能値が増えているだけなので1本あたりのディスクのI/O性能は変わりません。
- i3en.3xlargeは7.5TBのディスクが1本
- i3en.6xlargeは7.5TBのディスクが2本
- i3en.12xlargeは7.5TBのディスクが4本
仮に12xlargeを使ってもディスク1本のファイルシステムのI/O性能は3xlargeと同じです。その1本のディスクがAWS最速です。
(RAID0で複数のディスクをストライピングする)
カッコにしている理由は、現在はこれを使っていないからです。
過去にx1という巨大なメモリのインスタンスタイプで使ったときはRAID0を使ってないときより使ったときのほうがパフォーマンスは向上しました。
しかし現在使っているi3enのNVMe SSDのI/Oの速さは、メモリと比較して1:10~1:100ぐらいに近づいてきていることもあってか、RAIDを組んでもそれ以上速くならないようです。
WiredTigerのキャッシュ割当をサーバメモリの70%まで引き上げる
WiredTigerのキャッシュサイズを指定することができます。(フルマネージドのAtlasでは変更不可)
- wiredTigerCacheSizeGB
- 50% of (RAM - 1 GB) (デフォルト)
デフォルトはおおむねサーバメモリの50%だと考えれば良いと思います。余ったメモリはファイルシステムキャッシュで使います。ディスク上のファイルと同様に圧縮されたデータがファイルシステムキャッシュ上に置かれます。
NVMeやSSDが登場する前はディスクアクセスが少しでも発生すればたちまちレイテンシが高くなりましたが、昨今はディスクのI/O性能が上がって、従来は数千倍〜数万倍あったメモリに対する速度差は小さくなっています。WiredTigerに割り当てる分を多くして、ファイルシステムに残る分を少なくしても、全体としてのパフォーマンスが向上する可能性があります。
WiredTigerのキャッシュに60~70%ぐらいまで割り当てることができるのではないかという仮説を立てました。MongoDB Atlasではどれくらい割り当てているのかを計算したところ、WiredTigerのキャッシュに70%を割り当てていることがわかり、今ではAtlas以外の一部の本番環境でもそれを採用しています。
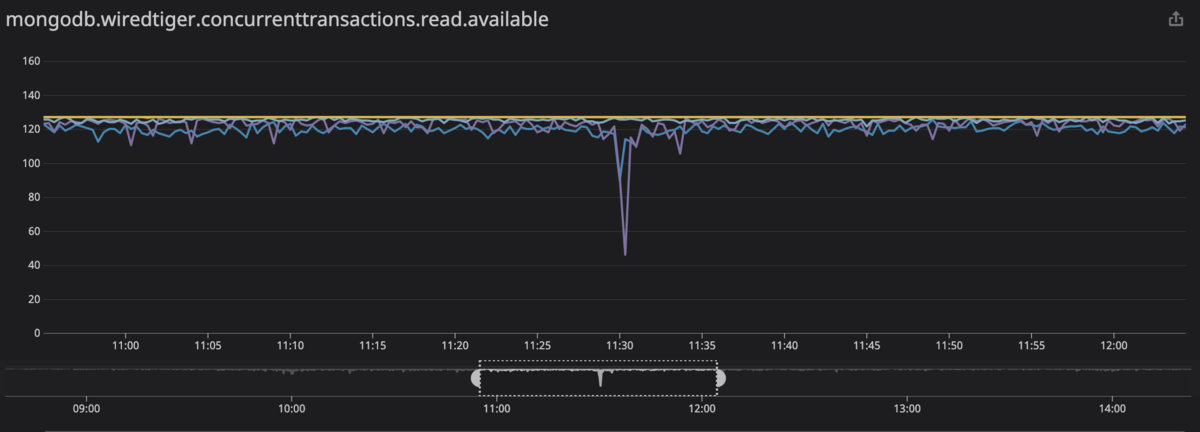
WiredTigerのTickets数を増やす
WiredTigerのRead/Writeの同時処理数を制限するこれらのパラメータはデフォルトで128になっています。
NVMe SSDのように高速なデバイス、かつ、十分なコア数のCPUを持つサーバでは128という数がボトルネックになります。 CPU使用率やiowaitがボトルネックになっていないなら、この値を増加させて問題ないと考えます。
利用可能なTicketsがどれだけあるのかを管理画面やDatadogで確認することができます。ただしメトリクスの集計と集計の間にTicketsが足りない状態になってもグラフでは検出できないことがあるので注意が必要です。
たとえば128のTicketsを数秒間使い切ってもメトリクスを集計するタイミングで使い切っていなければグラフでも使い切ってないように表示されますが、実際に使い切ったその数秒間は他のクエリを処理できません。
おわりに
必ずしもすべてのユースケースで当てはまるとは限りません。実際のパフォーマンス・チューニングにおいて大切なことは「推測するな、計測せよ」です。
ここで紹介したのは、DBを分割する前にできることですが、成長し続けるプロダクトにおいてスケーラビリティを確保するためには、DBをコレクションごとに分けたり(垂直分割)、シャーディングをしたり(水平分割)する必要があります。
2020年、Quipperの新たな挑戦が始まっています。日本、そして世界のオンライン教育を支えるSREの仲間を募集しています!
深尾もとのぶ