こんにちは。SRE の @chaspy です。
Quipper では Kubernetes Horizontal Pod Autoscaler (以下、HPA) を利用して Pod のオートスケーリングを実現しています。
HPA は非常に便利で、ほとんどのトラフィック増減に対応できます。しかし、オートスケーリングの宿命ではありますが、突発的なアクセス、いわゆるスパイクアクセスにはどうしても対応できません。CPU 利用率が急激に上がり、HPA がすぐに Desired Replicas を増やしたとしても、Node*1 のスケールアウトに5分程度はかかってしまいます。
CPU 使用率に基づくオートスケーリングに対して、決まった時間に決まった個数を事前にスケールしておくことを Scheduled-Scaling と呼ぶことにしましょう。前者のオートスケーリングと併用して Scheduled-Scaling を行う最も単純な方法は HPA の minReplicas を決まった時間に変更することです。1度だけの場合や、毎日同じ時間であればこれで十分かもしれませんが、スパイクが予測される時刻がバラバラの場合、minReplicas を変更を都度行うのは困難でしょう。
本記事では、実際にフィリピンで行われている定期試験*2で発生したスパイクアクセスに対して、Kubernetes HPA External Metrics を用いて Scheduled-Scaling を実現した事例を説明します。
背景: フィリピンにおける定期試験での Quipper の利用
フィリピンでは Quipper は学校に導入されており、定期試験に使われています。この試験は先生が事前に試験問題をシステム上に登録し、決まった時刻になったら対象生徒が試験を開始可能になります。
残念なことに、試験開始時刻にアクセスが集中してしまい、試験開始できる生徒と開始できない生徒がでてしまいました。言うまでもなく試験は学生にとって重要です。試験が受けられないこと、あるいは試験の開始時刻が遅れることによって学校現場や Customer Success チームに混乱と苦労を与えてしまいました。
まずは短期対策として、日中の時間帯のみ HPA の minReplicas を十分に大きい値にすることで、サービスダウンを回避しました。しかし、これでは余剰にサーバコストがかかってしまいます。


この問題に対して、Global Division Director の @naotori から、事前にデータベースにある試験開始時刻とアクセスが想定されるユーザ数をもとにサーバをスケールできないか?と相談を受けました。その後 Global Product Development VPoE の @bdesmero がデータベースから上記のデータを取得するバッチを書いてくれました。そのデータと実際のサーバに関する Metrics を観察したところ、サーバ負荷は取得した時刻とユーザ数に相関があることがわかりました。また、実際にアクセスを受け付けきれなかった時の Metrics から、現状のアーキテクチャにおける最大許容ユーザ数もわかりました。*3
そこで我々は、現在余剰にスケールアウトしている Pod 数を最適化するため、@bdesmero が取得したデータを HPA の External Metrics として採用し、CPU によるオートスケーリングと併用することで安全に Scheduled-Scaling を実現することにしました。
前提: HPA External Metrics と Datadog Custom Metrics Server
HPA といえば CPU に基づくオートスケールが広く知られていますが、 api version autoscaling/v2beta1 からは External Metrics に基づくオートスケールが利用できます。Quipper では Datadog を採用しているため、Datadog の metrics を利用する方法を考えました。
では、Datadog の metric によるオートスケールはどのように実現するのでしょうか。HPA (Controller) は Kubernetes metrics api (metrics.k8s.io, custom.metrics.k8s.io, external.metrics.k8s.io) から metrics を取得する仕組みになっています。
Datadog Custom Metrics Server の Document にしたがってセットアップすることで、API Service が追加されます。*4 API Service を登録することにより Kubernetes API の Aggregation Layer に登録され、HPA は Kubernetes API 経由で Datadog の Metrics Server*5 から metrics を取得できるようになります。図に表すと以下のような形になります。

さらに Datadog の metrics query を使いたい場合は、datadogmetric という CRD を登録します。*6
まず、cluster-agent が HPA の spec.metrics field が external かどうかを確認し、datadogmetric@<namespace>:<name> のような metric name を Parseしたのち、HPA の Reference Field をセットします。
そして HPA は Reference にセットされた内容で metrics server に問い合わせ、それを受けた cluster-agent は Datadog から取得した query を返却します。ちなみに都度 Datadog に問い合わせるのでなく、Controller が Reconcile Loop で取得したものを Local Store として保存し、datadogmetric resource に Sync しているようです。
アーキテクチャ
次に、Datadog metrics server と HPA を使った Scheduled-Scaling を実現するアーキテクチャを説明します。
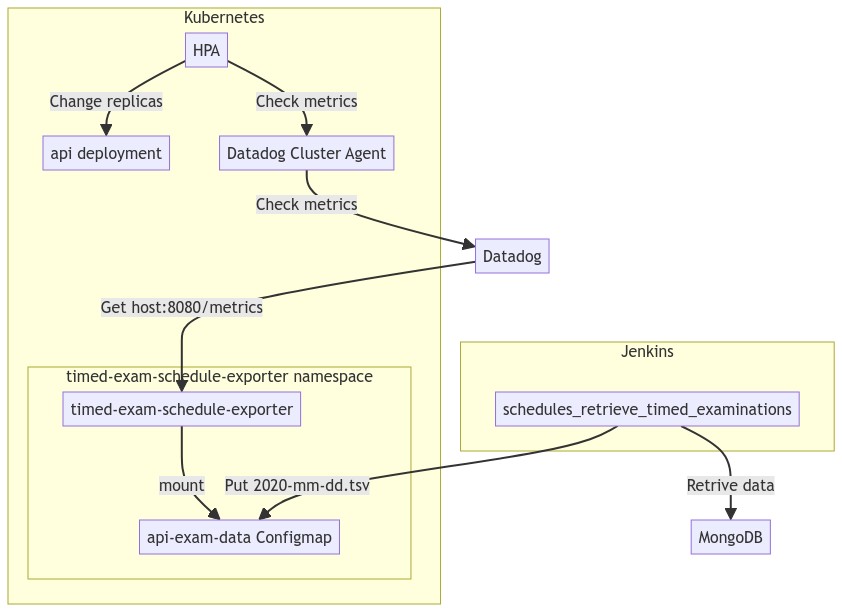
データベースからデータを Fetch して Configmap として保存する
右下の schedules_retrive_timed_examinations の周辺に着目ください。この部分は @bdesmero が作ってくれた部分です。試験開始時間とそれに対応する対象ユーザ数をデータベースから取得し、tsv として保存します。tsv はこんなイメージです。
12:00 229 12:15 54 12:45 67 13:00 3684 13:15 91 13:30 4821 13:45 37 14:00 138
この部分は Web Developer が責任を持ってやってくれたことでうまく分業ができました。Jenkins に依存している点、Configmap を経由している点と障害点が増えてしまうのは事実ですが、最短時間で、かつ Web Developer と分業してやるためには妥当な選択だと思います。*7
tsv から読み取ったデータを Prometheus 形式で export する
次に左下の timed-exam-schedule-exporter というコンポーネントをみていきましょう。このコンポーネントが今回私がメインに開発した部分です。Go で書かれており、Kubernetes Deployment として動いています。
やっていることは以下のようにシンプルです。
- configmap を mount
- 無限ループでファイルを読み取る
- 現在時刻と比較
- 該当するユーザ数を prometheus 形式で export
ポイントは現在時刻より15分後の値を Export する点です。Node / Pod がスケールする時間を考えると、実際にユーザがアクセスする15分前にスケールアウトを開始してほしいからです。
180行と大きくないのでコードを見てみましょう。
package main import ( "encoding/csv" "errors" "fmt" "io" "log" "net/http" "os" "strconv" "time" "github.com/prometheus/client_golang/prometheus" "github.com/prometheus/client_golang/prometheus/promhttp" ) var ( //nolint:gochecknoglobals desiredReplicas = prometheus.NewGauge(prometheus.GaugeOpts{ Namespace: "timed_exam", Subsystem: "scheduled_scaling", Name: "desired_replicas", Help: "Number of desired replicas for timed exam", }) ) func main() { const interval = 10 prometheus.MustRegister(desiredReplicas) http.Handle("/metrics", promhttp.Handler()) go func() { ticker := time.NewTicker(interval * time.Second) // register metrics as background for range ticker.C { err := snapshot() if err != nil { log.Fatal(err) } } }() log.Fatal(http.ListenAndServe(":8080", nil)) } func snapshot() error { const timeDifferencesToJapan = +9 * 60 * 60 tz := time.FixedZone("JST", timeDifferencesToJapan) t := time.Now().In(tz) today := t.Format("2006-01-02") // Configmap is mounted filename := "/etc/config/" + today + ".tsv" file, err := os.Open(filename) if err != nil { return fmt.Errorf("failed to open file: %w", err) } defer file.Close() currentUsers, err := getCurrentUsers(t, tz, file) if err != nil { return fmt.Errorf("failed to get the current number of users: %w", err) } desiredReplicas.Set(currentUsers) return nil } func getCurrentUsers(now time.Time, tz *time.Location, file io.Reader) (float64, error) { const metricTimeDifference = +15 // read input file reader := csv.NewReader(file) reader.Comma = '\t' // line[0] is time. i.e. "13:00" // line[1] is users. i.e. "350" var previousNumberOfUsers float64 // A variable for storing the value of the previous loop var index int64 for { index++ parsedTSVLine, err := parseLine(reader, now, tz) if errors.Is(err, io.EOF) { return previousNumberOfUsers, nil } if err != nil { return 0, fmt.Errorf("failed to parse a line (line: %d): %w", index, err) } // Example: // line[0] line[1] // 17:00 4 // 17:15 10 // // Loop compares the current time with the time on line[0], // and if the current time is later than the current time, // the previous line[1] is used as gauge. // // To prepare the pods and nodes "metricTimeDifference" minutes in advance, // expose the value "metricTimeDifference" minutes ahead of the current value. // In the above example, it will expose 10 at 17:00. if parsedTSVLine.time.After(now.Add(metricTimeDifference * time.Minute)) { // If the time of the first line is earlier than the time of the first line, // expose the value of the first line. if previousNumberOfUsers == 0 { return parsedTSVLine.numberOfUsers, nil } else { return previousNumberOfUsers, nil } } previousNumberOfUsers = parsedTSVLine.numberOfUsers } } type tsvLine struct { time time.Time numberOfUsers float64 } func parseLine(reader *csv.Reader, now time.Time, tz *time.Location) (tsvLine, error) { line, err := readLineOfTSV(reader) if err != nil { return tsvLine{}, fmt.Errorf("failed to read a line from TSV: %w", err) } parsedTime, err := parseTime(line[0], now, tz) if err != nil { return tsvLine{}, fmt.Errorf("failed to parse time from string to time: %s: %w", line[1], err) } parsedNumberOfUsers, err := strconv.ParseFloat(line[1], 64) if err != nil { return tsvLine{}, fmt.Errorf("the TSV file is invalid. The value of second column must be float: %s: %w", line[1], err) } return tsvLine{ time: parsedTime, numberOfUsers: parsedNumberOfUsers, }, nil } func parseTime(inputTime string, t time.Time, tz *time.Location) (time.Time, error) { const layout = "15:04" // parse "13:00" -> 2020-11-05 13:00:00 +0900 JST startTime, err := time.ParseInLocation(layout, inputTime, tz) if err != nil { return time.Time{}, fmt.Errorf("failed to parse a time string %s (layout: %s): %w", inputTime, layout, err) } parsedTime := time.Date( t.Year(), t.Month(), t.Day(), startTime.Hour(), startTime.Minute(), 0, 0, tz) return parsedTime, nil } func readLineOfTSV(reader *csv.Reader) ([]string, error) { const columnNum = 2 line, err := reader.Read() if errors.Is(err, io.EOF) { return line, fmt.Errorf("end of file: %w", err) } if err != nil { return line, fmt.Errorf("loading error: %w", err) } // Check if the input tsv file is valid if len(line) != columnNum { return line, fmt.Errorf("the input tsv column is invalid. expected: %d actual: %d", columnNum, len(line)) } return line, nil }
main() と snapshot() の部分がこのデザインパターンの重要な点です。
main() では ticker によるバックグラウンド処理を行ったのち、http port 8080 で待ち受けます。
snapshot() でファイルを読み取り必要な値を取得し、それを desiredReplicas.Set(currentUsers) で Gauge metrics としてセットします。
その他は行を読み取ったりパースをする処理です。基本的に Prometheus Go client library では timestamp は現在時刻を設定されます。*8 Datadog では未来の10分以上、または過去の1時間以上を指定することはできない*9ため、15分後の値を現在時刻として Export しています。
export した metrics を get するとこんな感じになります。
# at another window # kubectl port-forward timed-exam-schedule-exporter-775fcc7c5b-qg6q6 8080:8080 -n timed-exam-schedule-exporter $ curl -s localhost:8080/metrics | grep timed_exam_scheduled_scali ng_desired_replicas # HELP timed_exam_scheduled_scaling_desired_replicas Number of desired replicas for timed exam # TYPE timed_exam_scheduled_scaling_desired_replicas gauge timed_exam_scheduled_scaling_desired_replicas 46
Export した metrics を datadog-agent に取得してもらう
Datadog の Kubernetes Integration Autodiscovery を活用します。Pod の annotation を見て metrics を取りに来てくれる便利な機能です。
deployment の manifest はこんな感じになります。
apiVersion: apps/v1 kind: Deployment metadata: name: timed-exam-schedule-exporter namespace: timed-exam-schedule-exporter labels: name: timed-exam-schedule-exporter spec: replicas: 3 selector: matchLabels: app: timed-exam-schedule-exporter template: metadata: labels: app: timed-exam-schedule-exporter annotations: ad.datadoghq.com/timed-exam-schedule-exporter.check_names: | ["prometheus"] ad.datadoghq.com/timed-exam-schedule-exporter.init_configs: | [{}] ad.datadoghq.com/timed-exam-schedule-exporter.instances: | [ { "prometheus_url": "http://%%host%%:8080/metrics", "namespace": "timed_exam", "metrics": ["*"] } ] spec: containers: - image: <aws-account-id>.dkr.ecr.<region-name>.amazonaws.com/timed-exam-schedule-exporter:<commit hash> name: timed-exam-schedule-exporter ports: - name: http containerPort: 8080 livenessProbe: initialDelaySeconds: 1 httpGet: path: /metrics port: 8080 resources: limits: memory: 100Mi requests: cpu: 100m memory: 100Mi volumeMounts: - mountPath: /etc/config name: config-volume volumes: - configMap: defaultMode: 420 name: api-exam-data name: config-volume
HPA で datadog の query を利用して Scale を行う
最後に左上の部分です。これも manifest を見た方が早いでしょう。
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: api spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: api minReplicas: 40 maxReplicas: 1000 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 60 # want 570 mcore of cpu usage. 570 / 950(requests) = 0.6 - type: External external: metric: name: datadogmetric@production:timed-exam target: type: AverageValue averageValue: 1
type: External の部分が今回新規で追加した部分です。なお HPA はスケールの基準となる metrics を複数指定でき、計算した値のうち大きい方を採用します。この素晴らしい仕組みのおかげで、基本は CPU によるスケーリングを行いながら、特定の時間だけ別の Metrics によるスケールを行う合わせ技が実現できます。
参照している DatadogMetric はこちらです。
apiVersion: datadoghq.com/v1alpha1 kind: DatadogMetric metadata: name: timed-exam spec: # throughput: 10 = 500 / 5000. 500 pods accept 5000 users. # ref: https://github.com/quipper/xxxxxxx/issues/xxxxx query: ceil(max:timed_exam.timed_exam_scheduled_scaling_desired_replicas{environment:production}/10)
tsv ファイルにはユーザ数が書いてあり、Datadog にある metric もそれです。1 ユーザに対して何 pod 準備が必要か、という計算をここで行っています。
Datadog の query を使うことでコードを書く量を減らせた点は非常によかったと思います。
適用方法
Staging で動作確認をしたあと、Production では以下の順序で適用しました。
- Production に configmap と
timed-exam-schedule-exporterを Deploy し、metrics を Datadog に送る - Datadog Metric とテスト用の HPA を適用し、HPA が期待通り動作するか確認する
- 本番アプリケーションの HPA を更新する。この際 minReplicas は大きいままにしておく
- 様子を見ながら徐々に minReplicas を下げていく
本番のスケーリングに関する設定変更であり、かつ連携箇所も多いのでかなり慎重に適用を行いました。
注意点として、datadogmetric だけ適用しても HPA から Reference されていない限り metric は取得されません。HPA Controller が metric を取得する際はじめて cluster-agent が datadogmetric の Query を実行し、ステータスを更新するからです。そのため dummy の application と HPA を用いて検証を行いました。
Datadog の custom metric と HPA の設定が正しいことがわかったら、minReplicas は従来の大きい値のまま適用し、徐々に下げていきます。実際の tsv ファイルを注視しながら、想定より大きい replicas が期待される点では人間の監視も行い、うまく動いていることを確認しました。
信頼性に関する想定質問
TSV ファイルが invalid な場合どうなるか
timed-exam-schedule-exporter は 0 を expose します。その場合は CPU でのスケールが行われます。
Datadog との通信に失敗した場合どうなるか
Datadogmetric が Invalid な status となり、HPA の external metric の計算結果が unknown になります。この場合は CPU でのスケールが行われます。*10
timed-exam-schedule-exporter がダウンした場合どうなるか
metrics は Datadog に expose されないため、datadog metric が invalid となります。上記と同じく cpu での スケールが行われます。
いずれも HPA の multiple metrics に関する挙動のおかげで、external metric がおかしくなっても CPU でスケールが継続できる点は非常に安心できますね。
効果
これまでの pod の数と Node の数です。
そしてこれが適用後1週間の Pod 数と custom metrics です。

なんということでしょう。Pod が必要な時間は CPU によるスケーリングが行われており、多数のユーザが期待されているところでは External Metrics によって Pod がスケールされていますね。
Node 数も以前より少なくなりました。面積が減っていることがコストを削減していることを示しています。日単位で見ると利用料金は $250 から $145 となり、月間約 $3150 の節約が試算できます。

定期試験のユーザ数というドメインデータに基づいた柔軟なスケーリングを実現し、人間の介在を無くすとともに、信頼性のために余分にかかっていたインフラコストを削減できました。ハッピー。
おわりに
今回、Datadog に負荷に比例するユーザ数を custom metrics として送信し、それを HPA から External Metrics としてスケールさせる方法を解説しました。HPA の multiple metrics により、これまで適用していた CPU によるスケールと併用しながら安全に Scheduled-Scaling を実現できました。これによりリソースの効率化と信頼性の両方を担保することができました。
この事例により、今後も HPA に External Metrics として Datadog の metric が採用できるようになりました。実際、PubSub などを利用する Worker は CPU がうまくフィットしないケースもあり、Queue Length によるオートスケールで安定運用が期待できます。
また、今回は SRE、Web Developer、Business Developer と立場の違うチーム間のコミュニケーションにより問題解決を行えた事例でした。我々 SRE は Kubernetes の HPA や Datadog の使い方を知っていても、サービスのドメイン知識にあたるデータベースの内容やアプリケーションの機能詳細は知りません。密にコミュニケーションを取り、問題を共有し、ともに向き合えたからこそ解決できた良い例だと思います。
Quipper では世界の果てまで学びを届けたい仲間を募集しています。なお、筆者が所属する SRE Team も募集中です。カジュアル面談もしくは応募お待ちしています。
*1:EC2 Instance のこと
*2:Timed Exam と呼んでいる
*3:最大許容ユーザ数がわかったことから、これらを超えないように Product Manager の @yojvestudio を中心に、セールスチームと協力して運用でカバーしてもらうことができました。
*4:cluster agent の RBAC の manifest rbac-hpa.yaml に API Service が含まれています
*5:実態は Datadog Cluster Agent
*6:https://docs.datadoghq.com/agent/cluster_agent/external_metrics/#autoscaling-with-custom-queries-using-datadogmetric-crd-cluster-agent--v170
*7:試験に関するデータ取得は MongoDB の Collection というドメイン知識が必要なため SRE の私が行うのは難しかったと思います。
*8:timestamp を指定することは可能。ref: https://godoc.org/github.com/prometheus/client_golang/prometheus#NewMetricWithTimestamp
*9:Timestamps cannot be more than ten minutes in the future or more than one hour in the past.